今天的文章中,我們會延續昨天的題目,聊聊 Booking.com 在模型上線後發現的有趣現象。最後,我會再跟大家分享經過這 30 天的鐵人挑戰賽後,我學到的事,以及是如何整理筆記的。
在訓練模型時,大家都希望模型有很好的表現,例如準確率高、錯誤率低等等,進而希望這些模型能夠為公司帶來商業價值。不過,令人驚奇的是,Booking.com 發現模型的表現和商業價值不一定是正相關。
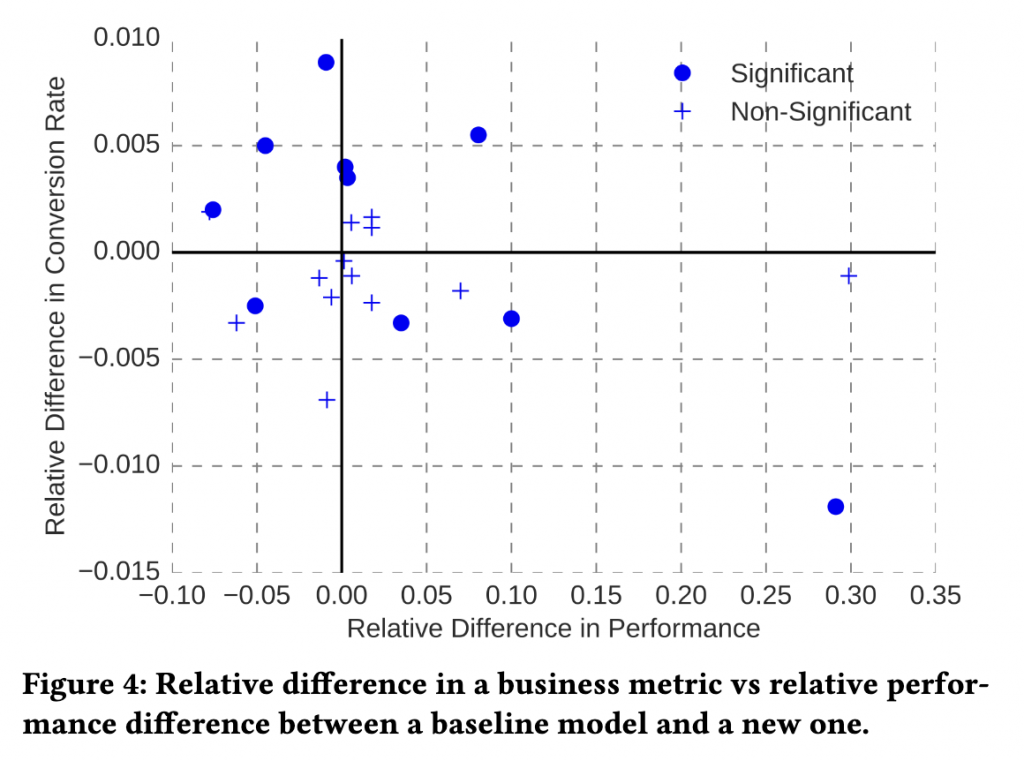
如 Figure 4 所示,他們將 23 個模型結果繪製在座標軸上,x 軸為新模型和舊模型(baseline)的表現差異,y 軸是轉換率(conversion rate)的變化。無需任何數值佐證,肉眼就可以看出這兩件事並沒有相關性。而兩者的 pearson correlation 為 -0.1(90% 的信賴區間為 (-0.45, 0.27)),更能推斷模型的表現和商業價值並無相關,此並非出自於線上和線下模型的差別。
值得一提的是,Booking.com 認為這個現象並不一定適用於每個狀況,還是要考慮模型使用的情景,並且他們也提出幾個可以解釋的原因。可能是因為模型表現率和價值的提升陷入停滯期,也有可能因為模型只是最大化某個可觀察行為,但不一定能夠轉化成商業價值。例如提升點擊數不代表能夠提升轉換率。舉一個實際的例子,模型可能會推薦給用戶一間非常相似於他現在正在查看的房源,進而吸引用戶點擊,但不代表用戶喜歡這間房源、更遑論能夠保證用戶會下訂了。
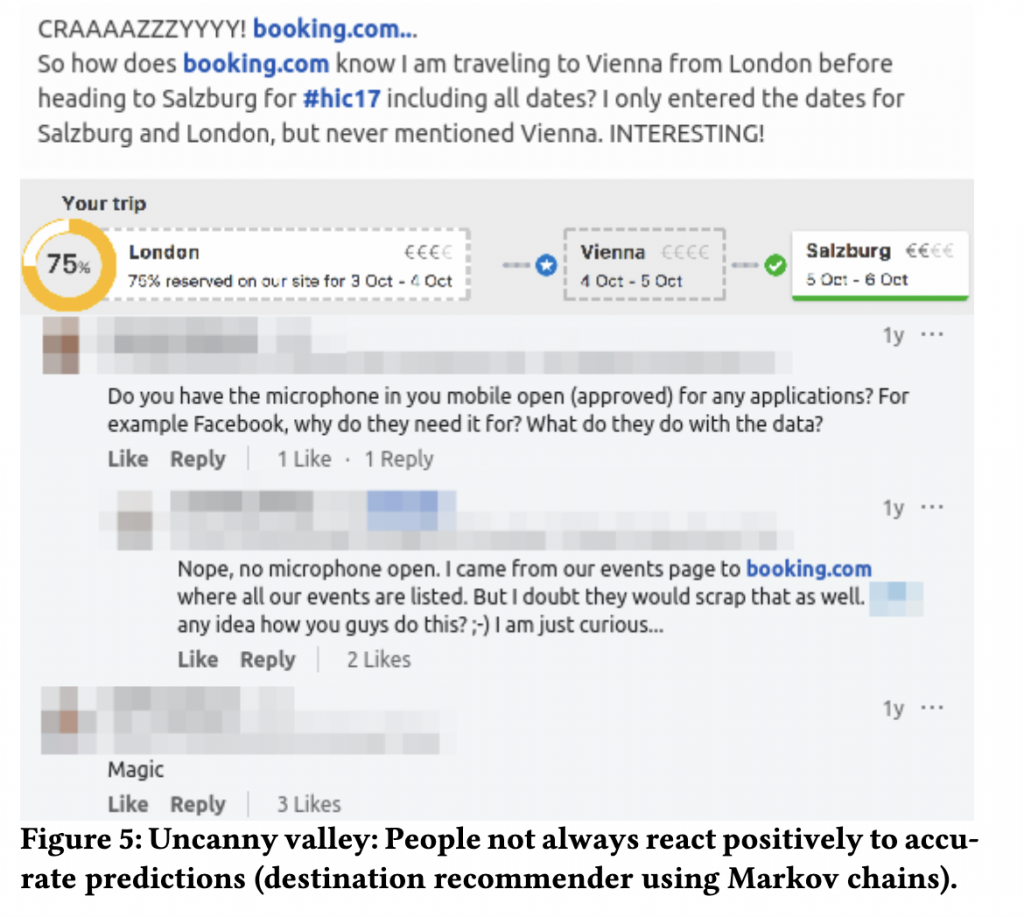
另外一個有趣的原因是「恐怖谷效應」,我相似大家一定都有類似的經驗,因為科技公司的推薦演算法太強大,能夠非常準確地預測用戶行為,反而讓我們時常懷疑手機在監聽自己。如 Figure 5 中的用戶對話,用戶 A 懷疑用戶 B 的手機麥克風是不是打開著?不然為什麼 Booking.com 知道他要去 Vienna,他明明只有輸入 Salzburg 和 London 這兩個目的地。
最後,我想花點篇幅聊聊本次鐵人賽的心得。
一開始比賽的初衷是因為希望能夠藉由比賽的時程壓力,逼迫自己閱讀科技公司的技術文章,並確實消化吸收。回首這一個月,的確有達成當初設下的目標,只是一邊工作一邊比賽真的有點吃力,更不用說每個週末都有安排行程,但幸好我還是成功地撐到最後一天了。
分享自己之後的兩個目標:
另外,也想介紹幾個助益良多的幾個工具:
雖然以上的工具看起來很多,不過使用起來都非常直覺好用,非常推薦大家用用看!
好的,以上就是我所有想說的話!雖然鐵人賽結束了,不過我還是會回去 medium 更新,歡迎大家轉去那邊繼續關注,我們後會有期!

謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
我的信箱是 shinminhsu@gmail.com,有任何問題也歡迎寄信聊聊。
Reference:
[1] L. Bernardi, T. Mavridis, and P. Estevez, “150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage AK USA, Jul. 2019, pp. 1743–1751. doi: 10.1145/3292500.3330744.


 iThome鐵人賽
iThome鐵人賽